Causal Inference Part 1: Causation and Correlation
Most of the time when we say “my model learned something,” what it actually learned is a bunch of very smart correlations. If users who click A also tend to click B, or if certain pixels tend to appear together in cat photos, our models will happily latch onto those patterns and exploit them. That’s powerful—and often enough for prediction—but it’s not the same as understanding what would happen if we actually changed something in the world: raised a price, changed a policy, or shipped a new feature.
This blog post is about that gap. We’ll look at how correlation-based learning differs from causal reasoning, why most ML lives firmly on the correlation side, and how ideas from causal inference help us talk more clearly about actions, interventions, and “what-if” questions.
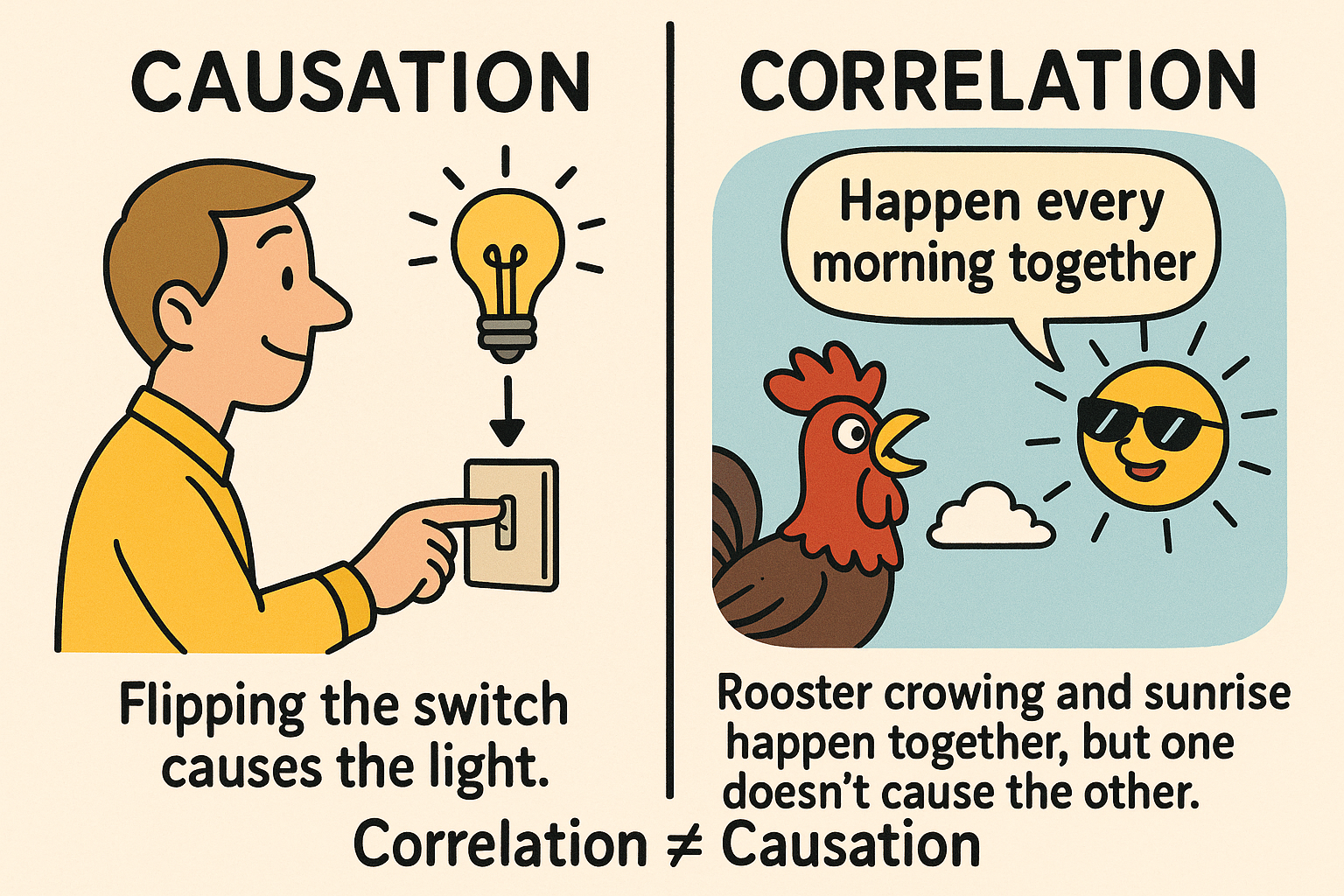
Correlation vs Causation
Before we talk about causal inference, it is useful to clarify a basic but crucial distinction: correlation versus causation.
Correlation: how things move together
Two variables are said to be correlated if they tend to move (or change) together in the data:
- When one variable is high, the other also tends to be high, or
- When one is high, the other tends to be low.
Formally, we can measure this with quantities such as covariance or correlation coefficients. Intuitively, correlation captures how much two variables vary in the data we observe.
A key point is that correlation is purely about patterns in the data, not about underlying mechanisms. If ice-cream sales and drowning accidents go up together in summer, they are correlated; but it would be absurd to say that buying ice cream causes drowning. Both are driven by a third factor: the weather.
Causation: how one variable affects another
By contrast, causation is about what happens to one variable if we change another variable:
If we force $X$ to change, how does $Y$ respond (on average)?
Here we are interested in the exact impact of one variable on another under interventions, not just how they happened to move together in the past. Causal questions are of the form:
- What is the effect of raising the legal driving age on traffic accidents?
- What is the effect of a new drug on blood pressure?
- What is the effect of a new recommendation algorithm on user engagement?
These questions all ask about the consequences of a hypothetical action, not just about existing correlations.
What most machine learning actually learns
Most standard machine learning algorithms (e.g., linear regression, logistic regression, random forests, neural networks, transformers, and so on) are trained to learn patterns like
$$P(Y \mid X) \quad \text{or} \quad f(x) \approx \mathbb{E}[Y \mid X = x],$$
that is, they learn to predict $Y$ from $X$ based on observed co-variation in the data. In other words:
- They learn correlations (or more generally, statistical dependencies) between inputs and outputs.
- They do not, by default, distinguish whether those dependencies are causal or simply due to confounding factors.
We can think of standard ML as correlation-based learning:
- It focuses on learning how variables change together in the data rather than understanding the underlying “why”,
- It focuses not on what would happen if we actively intervened and changed one variable while holding everything else fixed.
This distinction is crucial:
- A model that is excellent at exploiting correlations may be very good at prediction in environments similar to its training data,
- but it can fail badly when we change the environment or policy, because it does not know the underlying causal structure.
Causal inference, by contrast, aims precisely at learning (or using assumptions about) the causal impact of one variable on another.
In short, correlation-based learning is about capturing how variables change together in the observed world, while causal inference aims to characterize the direct impact of changing one variable on another under a specified intervention.
From correlation to intervention
In the rest of this post, we will move from correlation-based questions to truly causal ones. To do this, we will introduce the distinction between:
- Observations: passively watching the world as it is, and
- Actions (interventions): asking what would happen if we changed something in the world.
This will lead naturally to the language of causal reasoning, and to examples — such as driving-age policies — that illustrate why correlation alone is not enough.
Observations vs Actions
Let’s start with the difference between just watching the world and actually changing something in it.
- When we passively observe, we simply watch how people normally behave, following their habits, routines, and preferences.
- The data we collect in this way are like a snapshot of the world as it currently is, summarized in whatever features we decided to record (e.g., age, income, accident history).
This kind of data is called observational data. So what can we answer with observational data? Some questions fit perfectly into this observational world. For example:
Example
Do 16-year-old drivers have more traffic accidents than 18-year-old drivers?
This is a question about how often something happens in the world as it is.
Mathematically, we can compute:
- the (conditional) probability of an accident given that the driver is 16.
- the (conditional) probability of an accident given that the driver is 18.
Then compare those two numbers (e.g., subtract them).
If we have a large enough sample with both 16- and 18-year-old drivers, we can estimate these probabilities directly from the data using standard observational statistics.
Now consider a slightly different question:
What would happen to traffic fatalities if we raised the legal driving age by two years?
This sounds similar, but it’s actually a different type of question.
- The previous question was about how often something happens in the current world.
- This new question is about what would happen if we changed the rules of the world.
That is, it’s asking about the effect of a hypothetical action (an intervention): “Raise the driving age -> what changes?”
You can’t answer that reliably just by looking at current accident rates by age, because:
- Maybe older drivers crash less simply because they have more experience, not because they’re older.
- An 18-year-old with only 2 months of driving experience might be no safer than a 16-year-old with 2 months of experience.
We could try to control for experience; for example, we can compare accident rates for people with the same number of months of driving, but different ages.
However, even then, we run into complications:
- What if 18-year-olds with two months of driving experience tend to be exceptionally cautious, but become less cautious as they gain more experience?
- Maybe they tend to live in areas where people do not need to start driving until later in life.
So even when you try to adjust for obvious factors like months of experience, other hidden differences can still mess up your conclusions.
We might try another strategy: compare countries with different legal driving ages, like the US and Germany. These countries differ in many ways besides driving age:
- Public transport, culture, enforcement, and even laws, like the legal drinking age.
So differences in accident rates could be caused by any of those factors, not just the driving age.
This is where causal reasoning comes in. Causal reasoning is a framework — both conceptual and technical — for answering questions like:
- What is the effect of doing $X$? (e.g., raising the driving age)
- What action caused $Y$? (e.g., what policy likely reduced accidents?)
It focuses on interventions:
- Not just what is the world like?
- But what would the world look like if we changed something?
Once we understand how to define and estimate the effect of an action, we can turn questions around and ask:
Given that we observed this outcome, what actions or causes are likely responsible?
To formalize the concept, let’s see how the limits of pure observation show up in real data.
The limitations of observation
In 1973, researchers looked at graduate school admissions at the University of California, Berkeley. They had data on 12,763 applicants across 101 departments and programs.
- About 4,321 of these applicants were women, and roughly 35% of them were admitted.
- About 8,442 were men, and around 44% of them were admitted.
Just looking at these totals, it seems like men were more likely to be admitted than women (44% vs 35%). Standard statistical tests say this difference is too big to be explained by random chance alone, so it looks like a real gap.
The same pattern appeared when the researchers focused on the six largest departments:
- Across these six, men again had an overall acceptance rate of about 44%,
- while women had an overall rate of about 30%.
Again, this suggests that men are doing better than women when you look at the data in aggregate (all combined).
However, each department decides who to admit by itself, and departments can be very different — different fields, different standards, different competitiveness. So the researchers drilled down and looked at the acceptance rates within each of those six big departments.
What they found was surprising:
- In four of the six departments, women actually had a higher acceptance rate than men.
- In the other two departments, men had the higher acceptance rate.
But those two departments weren’t big enough or different enough to explain the large overall gap in the combined data.
We can find a reversal:
- Overall across departments: men seem to be favored.
- Inside most departments: women do as well or better than men.

This is an example of what’s often called Simpson’s paradox: a situation where a pattern that appears in overall (aggregate) data reverses when you break the data into subgroups.
In this case:
- Event $Y$: the applicant is accepted.
- Event $A$: the applicant is female (gender treated as a binary variable).
- Variable $Z$: which department the applicant applied to.
Simpson’s paradox means it can happen that:
- For each department ($Z$), women might do as well as or better than men:
$$P(\text{accepted} \mid \text{female}, Z) \ge P(\text{accepted} \mid \text{male}, Z),$$ but
- Overall, women still have a lower acceptance rate than men:
$$P(\text{accepted} \mid \text{female}) < P(\text{accepted} \mid \text{male}).$$
This happens because men and women apply to different departments in different proportions, and those departments have different levels of competitiveness.
From the data, one thing is very clear: Gender affects which departments people apply to. Men and women have different patterns of department choice.
We also know that departments differ in how hard it is to get in. Some have low acceptance rates (very competitive), others have higher acceptance rates.
So one plausible explanation is:
- Women tended to apply more to highly competitive departments, while men applied more to less competitive ones.
- As a result, women were rejected more often overall, even though departments themselves may have treated individual male and female applicants fairly.
This was essentially the conclusion of the original study. They argued:
- The bias seen in the combined statistics does not come from admissions committees systematically discriminating against women.
- Instead, it comes from earlier stages in the pipeline: the way society and the education system have steered women toward certain fields.
They suggested that women were shunted by their upbringing and education into fields that:
- are more crowded,
- have fewer resources and funding,
- have lower completion rates,
- and often lead to poorer job prospects.
In other words, they said the gender bias was mainly a pipeline problem1: by the time women reached graduate applications, they were already concentrated in less favorable, more competitive fields, through no fault of the departments themselves. However, it’s hard to fully defend or criticize that conclusion using this data alone, because key information is missing.
For example, we don’t know why women chose those more competitive departments:
- Maybe some less competitive departments (like certain engineering programs) were unwelcoming to women.
- Maybe some departments had a bad reputation for how they treated women, so women avoided them.
- Maybe the way departments advertised or described themselves discouraged women from applying.
We also don’t know anything about the qualifications of applicants:
- It could be that, because of social barriers, women who applied to engineering in 1973 were on average more qualified than the men who applied.
- In that case, if the acceptance rate for men and women is equal, it might actually mean women are being held to a higher bar, which would be discrimination.
So, the observed acceptance rates alone cannot tell us whether there was discrimination or not. They leave us with many plausible stories, and we can’t distinguish between them without more information.
Given this uncertainty, there are two possible options:
Design a new study and collect better data.
- Measure more variables (like applicant qualifications, department culture, prior experiences, etc.).
- This might allow a more conclusive answer about discrimination.
Stay with the current data and argue using assumptions and background knowledge.
- Use what we know about the social context of the 1970s, academic culture, and gender norms.
- Then argue about which explanation is more likely:
- Is it mostly a neutral pipeline effect?
- Or a mix of pipeline factors and discrimination at various stages?
Causal models as a bridge between data and assumptions
Up to this point, we have seen two recurring themes:
- Observational data alone can be ambiguous: the same pattern can be explained by multiple causal stories.
- Policy questions (“what if we changed $X$?”) are fundamentally about interventions, not just about correlations.
Causal models provide a way to organize both of these issues. They give us:
- A way to distinguish between observing and doing,
- A structured way to encode assumptions about how variables influence one another,
- A toolkit to derive the effect of hypothetical actions from observational data when possible.
Observation vs intervention in notation
In ordinary statistics, we are used to working with conditional probabilities of the form
\begin{align*} P(Y \mid X = x), \end{align*} which answer questions of the form:
Among the individuals for whom we see $X = x$, how often do we see $Y$?
For example, $P(\text{accident} \mid \text{age}=16)$ is the accident rate among all drivers who happen to be 16 in our data.
Causal questions, by contrast, refer to the effect of an action. For this we introduce the notation
\begin{align*} P(Y \mid \operatorname{do}(X = x)), \end{align*} which answers:
If we were to force $X$ to take the value $x$ (by intervention), how often would we see $Y$?
In the driving-age example, $P(\text{accident} \mid \operatorname{do}(\text{min.\ age}=18))$ describes the accident rate we would expect under a policy that sets the legal driving age to 18, taking into account all downstream changes (e.g., who drives, when they start, how much experience they accumulate).
In general, \begin{align*} P(Y \mid X = x) \neq P(Y \mid \operatorname{do}(X = x)), \end{align*} since individuals who happen to have $X = x$ in the observational world may differ in systematic ways from those who would end up with $X = x$ under an intervention. This discrepancy is precisely what we saw in the Berkeley example and the driving-age discussion: simple conditioning on (X) mixes together many other influences.
Causal diagrams (informally)
One convenient way to encode assumptions about how variables influence each other is via causal diagrams, also called directed acyclic graphs (DAGs). For the driving-age example, a highly simplified diagram might look like:
Law → Age at start → Experience → Accidents
| / |
| / |
| / |
Personality RegionRead informally, this says:
- The Law constrains the age at which people can start driving.
- Age at start influences how much Experience they can accumulate.
- Experience influences the risk of Accidents.
- Personality (cautious vs reckless) affects both how much Experience people seek and their risk of Accidents.
- Region (urban vs rural, road conditions, etc.) also affects Accidents.
This kind of diagram helps us see why simply comparing $P(\text{Accidents} \mid \text{Age})$ can be misleading:
- Age is entangled with Experience, Personality, and Region.
- Changing the Law changes Age, which in turn changes Experience and who drives at all.
Causal calculus (Pearl’s do-calculus) tells us when and how we can recover $P(Y \mid \operatorname{do}(X=x))$ from purely observational data given such a diagram, and when we cannot.
Designing better studies
Causal models are not only a tool for interpreting existing data; they also guide the design of new studies. Given a causal diagram, we can ask:
- Which variables must we measure in order to block spurious associations (confounding paths)?
- Which variables should we not condition on, because they may introduce new biases (colliders)?
- Under what conditions can we estimate causal effects from purely observational data?
In the Berkeley example, a causal model could tell us that we are missing key variables, such as:
- Applicant qualifications (grades, test scores, research experience),
- Department climate or reputation for treating women,
- Broader social forces shaping field choice.
The model would then make explicit that, without additional measurements or assumptions, certain causal questions (e.g., “Was there discrimination at the department level?”) cannot be answered definitively from the existing data.
Reasoning with incomplete data
Even when we cannot collect more data, causal models still have value. They allow us to:
- Enumerate different plausible causal stories consistent with the observed data,
- Explore the implications of each story (“If the world worked this way, what would the effect of changing (X) be?”),
- Identify which assumptions are doing the real work in our conclusions.
In other words, a causal model acts as a logic engine for cause-and-effect reasoning: given explicit assumptions, it yields explicit conclusions, and it clarifies which parts of our reasoning depend on empirical evidence and which parts depend on judgment and prior knowledge.
Summary
We can now summarize the main points:
- Observational data show us how the world is, not automatically how it would be if we changed something.
- Questions about policies or interventions (raising the driving age, changing admissions rules, etc.) are inherently causal and require reasoning about $\operatorname{do}(\cdot)$, not just conditional probabilities.
- The Berkeley admissions example illustrates how aggregated patterns can reverse when we condition on a relevant variable (department), a phenomenon known as Simpson’s paradox.
- Observational patterns alone can be compatible with multiple causal explanations (pipeline effects, discrimination at various stages, or both); data without a causal model cannot fully resolve such ambiguities.
- Causal models provide a structured way to:
- Distinguish observation from intervention,
- Design better studies and decide which variables to measure or control,
- Connect domain knowledge and assumptions to concrete, testable implications.
In this sense, causal inference is not just an add-on to statistics but a complementary framework that lets us talk rigorously about actions, policies, and the mechanisms that generate the data we see.
Reference
- Patterns, predictions, and actions: A story about machine learning, Moritz Hardt, Benjamin Recht, 2021
This term describes a situation where the number of people, particularly women, decreases at each successive stage of a career pipeline, leading to a significant underrepresentation at the top levels. ↩︎